Microsoft 연구원은 최근 ChatGPT의 기능을 Stable Diffusion과 같은 시각적 기반 모델과 결합하는 것을 목표로 하는 논문을 발표했습니다. Visual ChatGPT라고 불리는 이 아키텍처는 텍스트-이미지 생성과 자연어 생성 간의 격차를 해소하려고 시도합니다.
AIM이 예측한 대로 이것은 텍스트-이미지 알고리즘이 나아갈 방향으로 보입니다. 이 접근 방식은 ChatGPT와 같은 LLM의 강점을 이미징 기능과 결합하여 두 플랫폼의 단점을 모두 포괄하는 포괄적인 패키지를 제공합니다. 파라메트릭 이미징 모델에 자연어 처리를 도입하여 보다 유기적인 방식으로 AI와 상호 작용할 수 있습니다.
Visual ChatGPT는 어떻게 작동하나요?
간단히 말해 Visual ChatGPT는 이미지 공유 기능이 추가된 ChatGPT 기술입니다. 이 기능은 Stable Diffusion, ControlNet, BLIP 및 ChatGPT 자체와 같은 다양한 시각적 기반 모델 간에 정보를 공유하는 “프롬프트 관리자”를 사용하여 달성됩니다.
Command Prompt Manager는 ChatGPT를 이러한 VFM과 연결하여 출력을 용이하게 합니다. 예를 들어 레스토랑 주방을 생각해 보십시오. ChatGPT가 고객 주문을 받는 웨이터와 같다면 VFM은 주방의 셰프와 같습니다. Prompt Manager는 헤드 셰프의 역할을 맡아 웨이터와 셰프 사이에서 주문과 요리를 전달합니다.
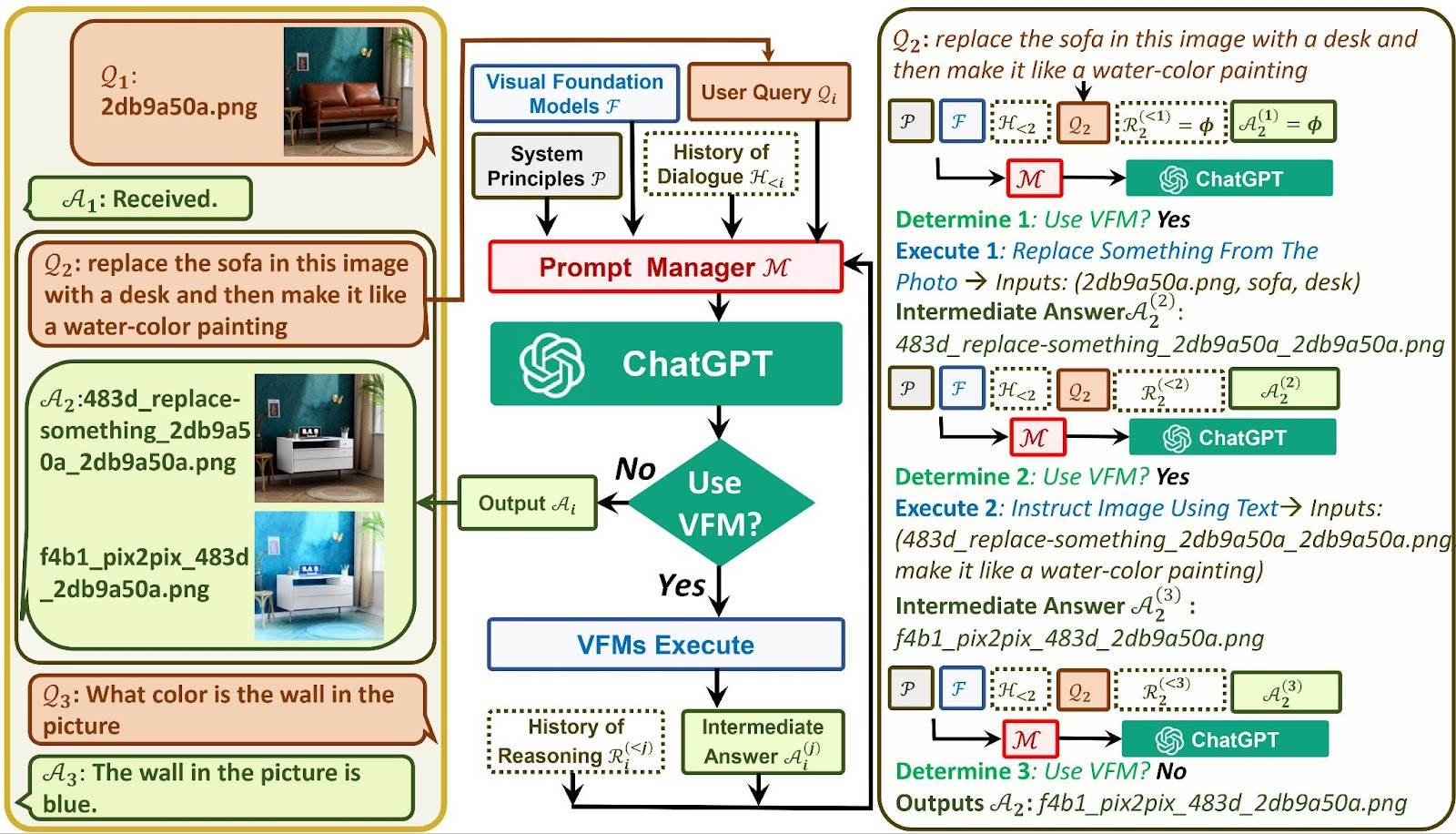
따라서 명령 프롬프트 관리자에는 다음과 같은 몇 가지 논리가 포함되어 있습니다. B. ChatGPT가 필요한 출력을 제공하기 위해 도구(예: VFM)를 사용해야 하는지 여부를 결정하는 데 도움이 되는 휴리스틱 양식. PM은 출력 이미지를 미세 조정하는 데 사용되는 반복 추론도 처리합니다. 또한 다음과 같은 특정 관리 작업을 처리합니다. B. ChatGPT 출력 파일 이름 관리 및 이미지 파일 이름 추적.
Prompt Manager는 ChatGPT가 모든 종류의 비음성 요청에 응답하기 위해 호출하기 때문에 실제로 이 시스템의 핵심입니다. Prompt Manager는 사용자를 대신하여 일련의 사용자 지정 가능한 프롬프트를 통해 ChatGPT를 필요한 출력으로 안내합니다. 그 결과 환각에 의존하지 않고 대신 명령 프롬프트 관리자를 통해 VFM의 기능을 호출하는 훨씬 더 강력한 버전의 ChatGPT가 탄생했습니다.
Visual ChatGPT는 그 자체로 훌륭하지만 더 흥미로운 선례를 설정합니다. LLM과 시각적 모델의 힘을 결합하는 것이 가능합니까? 그리고 이것이 AGI를 향한 첫 걸음 중 하나가 될 수 있을까요? 시작되었다고 생각합니다. 아직 갈 길이 멀지만 재미있습니다.
데모 비디오
Colab 사용해보기
아래는 시각적 ChatGPT Colab 사례에 대한 링크입니다.
https://colab.research.google.com/drive/11BtP3h-w0dZjA-X8JsS9_eo8OeGYvxXB
비주얼챗GPT
협업 노트북
colab.research.google.com
Colab 사용 방법을 알고 있다고 가정합니다.
각 행의 왼쪽에 있는 > 재생 버튼을 누르기만 하면 실행됩니다.
그리고 4번에 자신의 OPENAI_API_KEY를 입력합니다.

API를 노출할 수 있는 웹사이트 링크를 아래에 공유합니다.
https://openai.com/blog/openai-api
OpenAI API
OpenAI에서 개발한 새로운 AI 모델에 액세스하기 위한 API를 출시하고 있습니다.
openai.com
작업 결과를 보겠습니다.

잘 안되는게 뭐야…

그림을 보고 색상과 줄무늬를 신중하게 조정합니다.
모두가 시도합니다
텍스트를 이미지 변환으로 바꾸기
텍스트-이미지 모델이 작동하는 방식에는 근본적인 문제가 있습니다. 바로 언어적 맥락에 대한 이해 부족입니다. 생성적 AI 모델의 관계적 이해를 조사한 논문에서 연구원들은 이러한 모델이 특정 사물의 물리적 관계를 “이해”하지 못한다는 사실을 발견했습니다.
예를 들어, 모델은 “아이가 그릇을 만지고”에 대한 이미지를 생성할 수 있지만 “이구아나를 만지고 있는 원숭이”에 대한 이미지는 생성하지 않을 수 있습니다. 이는 후자의 시나리오에 대한 학습 데이터에 충분한 정보가 포함되어 있지 않아 부적절한 응답이 발생하기 때문입니다. 이러한 텍스트-이미지 모델의 한계를 극복하기 위해 AI Whisperer 또는 Prompt Engineering이라는 새로운 직업이 등장했습니다.
AI 모델이 인간을 “이해”하도록 하는 프로세스는 여전히 새로운 영역이며 신흥 AI 아티스트는 천천히 개척하고 있습니다. 이 때문에 다음과 같은 텍스트-이미지 변환 알고리즘 프롬프트 모음이 있는 웹사이트가 있습니다. 아래 예를 확인하십시오.

이 이미지에서 볼 수 있듯이 텍스트-이미지 모델에서 확실한 결과를 얻으려면 무엇을 프롬프트해야 하는지에 대한 광범위한 지식 기반이 필요합니다. 네거티브 프롬프트는 최종 이미지에서 특정 기능을 피하기 위해 사용되기도 합니다. 마이크로소프트의 Prompt Manager가 나아가고 있는 방향을 본다면 그 가능성은 무궁무진합니다.
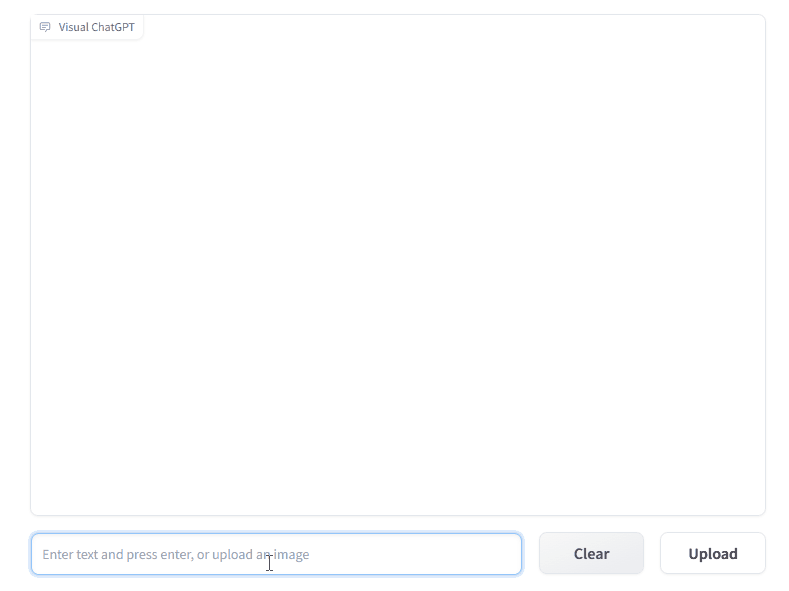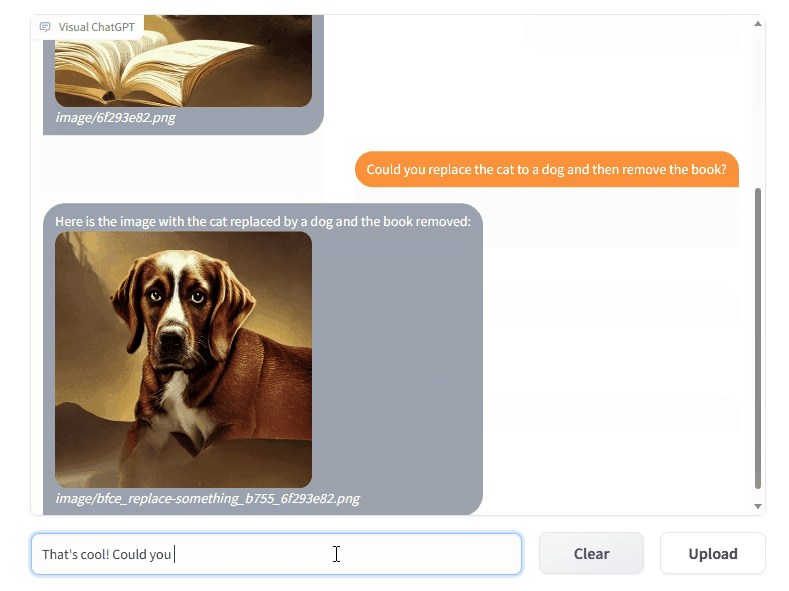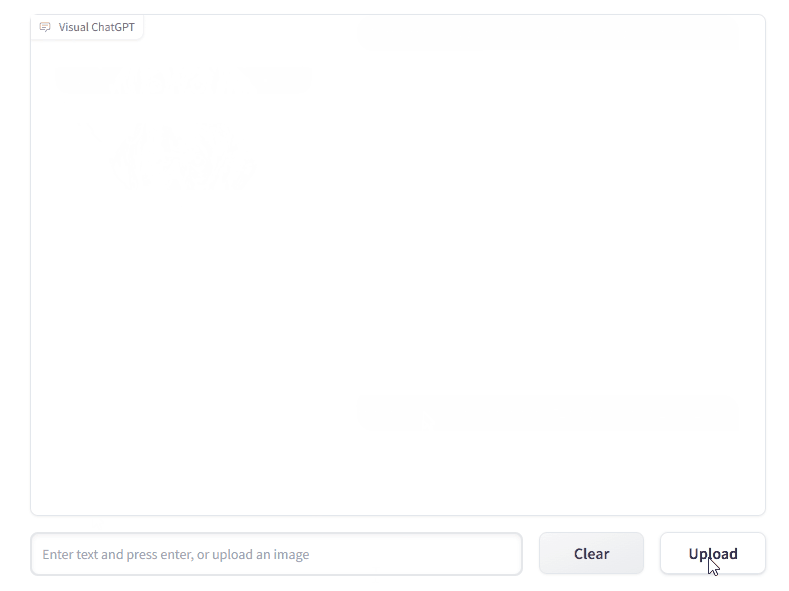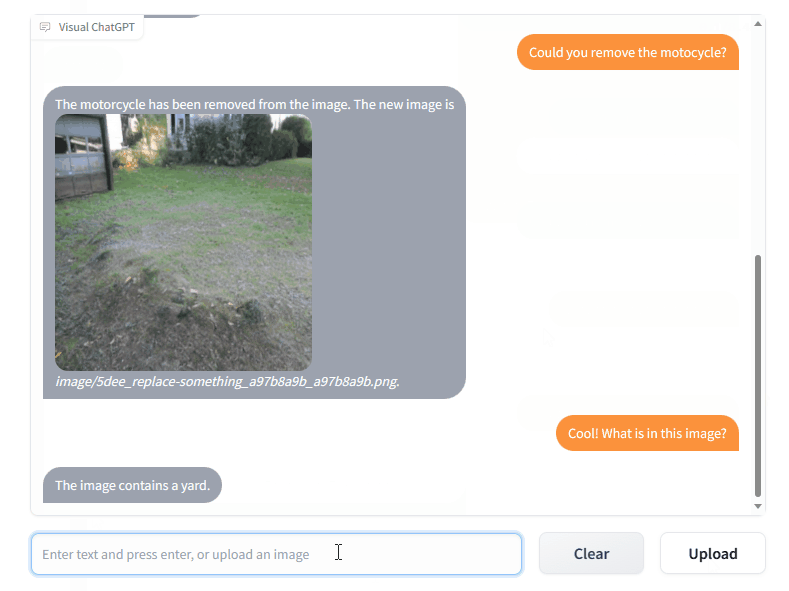
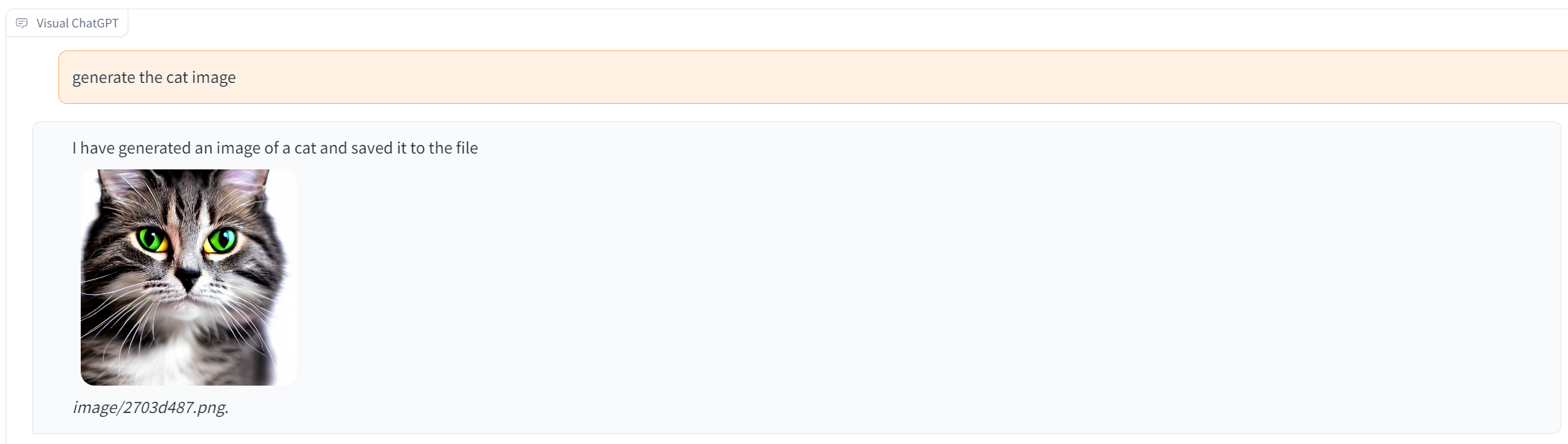
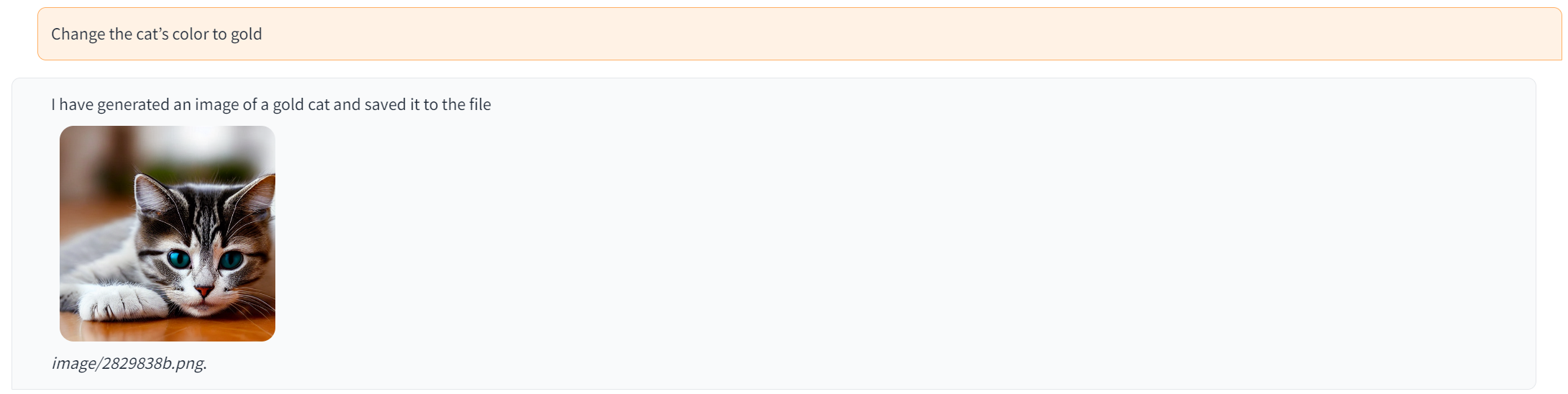
GitHub 페이지에 제공된 예제는 사용자가 모델에 정보를 전달하기 위해 복잡한 프롬프트를 처리할 필요가 없음을 보여줍니다. 사용자는 모델에 입력하고 싶은 내용을 자연어로 입력하기만 하면 됩니다. 예를 들어 사용자가 고양이 사진을 만든 다음 ChatGPT에 고양이를 개로 바꿔달라고 요청합니다. 복잡한 프롬프트 없이 이미지가 생성되며 사용자는 이미지를 반복적으로 변경할 수 있습니다. B. 색상을 변경합니다.
Visual ChatGPT와 같은 도구는 텍스트-이미지 모델의 진입 장벽을 낮출 수 있지만 다른 AI 도구의 상호 운용성을 개선하는 데에도 사용할 수 있습니다. 역사적으로 LLM 및 T2I 모델은 독립적으로 존재했지만 Prompt Manager와 같은 기술은 이러한 최신 모델의 기능을 확장할 수 있습니다.
2023/03/12 – (AI 설명) – 확산 모델 중 LoRA 모델에 대해 알아보고 이미지 생성
2023.03.12 – (AI 설명) – 유통 확장 모델인 드림부스 알아보고 이미지 만들기
2023-03-11 – (AI 설명) – Diffusion Technologies에서 Text Inversion을 속성으로 알아봅니다.
2023.03.02 – (No-coding AI) – Windows PC에 Stable Diffusion WebUI를 설치하여 실사 사진을 만드는 방법